My agent did the wrong thing perfectly, and that’s when I understood planning
I built an AI agent to help automate some research tasks. I gave it a goal: “Find the top five competitors for this SaaS product and summarize their pricing.” Simple enough. I ran it and walked away. When I came back, the agent had produced a beautifully formatted, deeply researched report on the wrong company. It had misread the first search result, anchored on that, and executed the rest of the plan flawlessly against a false premise.
The agent wasn’t unintelligent. It was actually impressive at execution. What it lacked was a planning system that could verify its own assumptions before committing to a direction. That single experience sent me down a rabbit hole into one of the most underappreciated areas of agentic AI: how agents plan.
If you’re building AI agents or trying to understand why yours behave unpredictably, understanding agent planning systems is the missing piece. This guide covers what planning is in the context of AI agents, the major strategies in use today, their tradeoffs, and how to choose the right one for your system.

What are agent planning systems, exactly?
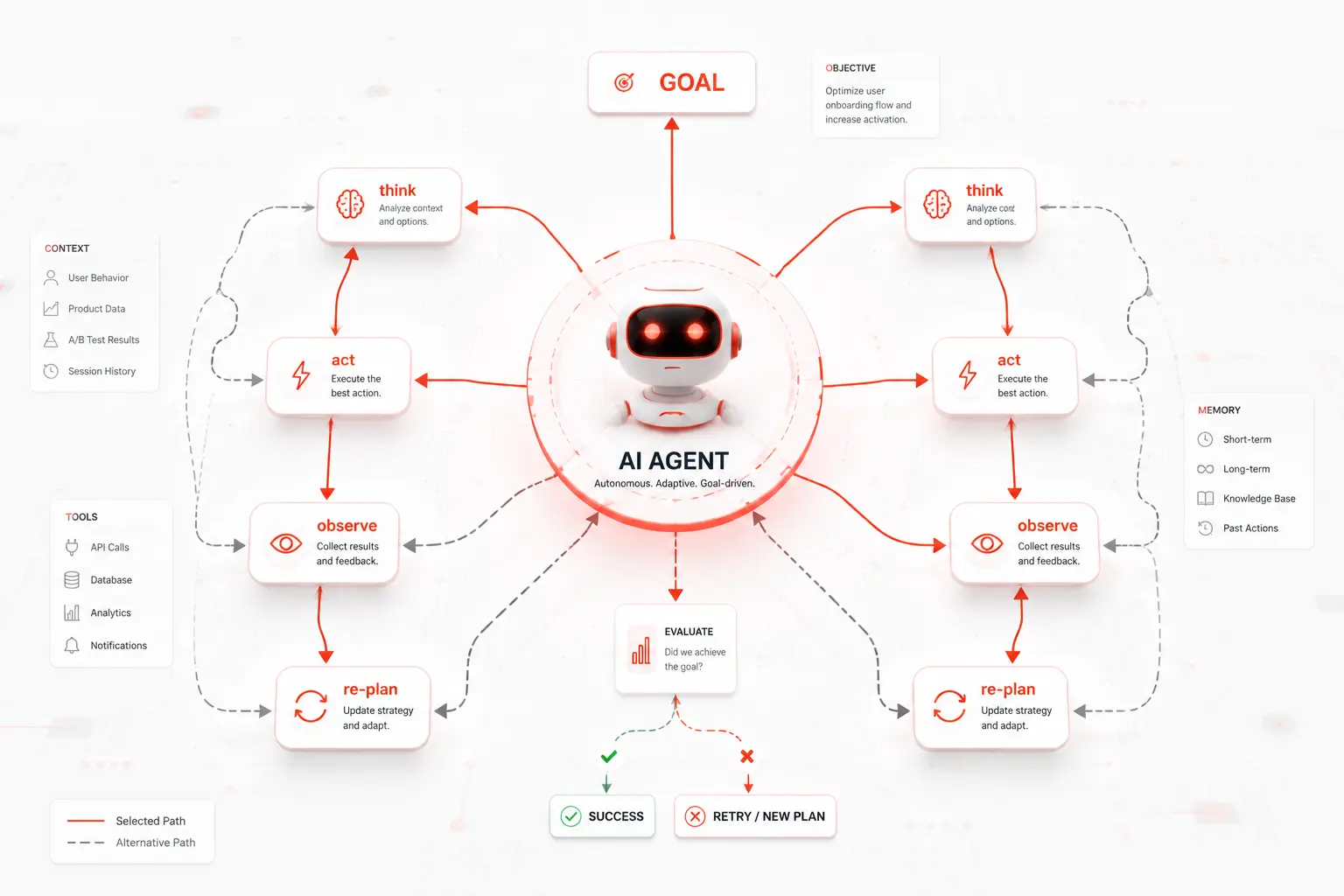
Agent planning is the process by which an AI agent breaks a high-level goal into a sequence of concrete, executable steps and decides, at each point, what to do next based on what it knows and what it has observed so far.
A human developer solving a complex task doesn’t just start typing. They read the requirements, identify unknowns, sketch an approach, execute steps, check whether each step worked, and adjust when something breaks. Agent planning systems replicate this loop in software.
Without a planning system, an agent is just a prompt-response machine fast, but brittle on anything requiring more than one step. With a planning system, the agent becomes capable of pursuing goals that require reasoning, tool use, error recovery, and multi-step coordination. That’s the difference between a chatbot and an agent.
Planning in AI agents involves three core activities:
- Decomposition: breaking a complex goal into smaller, manageable subgoals
- Sequencing and ordering those subgoals in a logical, dependency-aware way
- Adaptation: revising the plan when new information arrives or something fails
How a system handles these three activities defines which planning strategy it’s using.
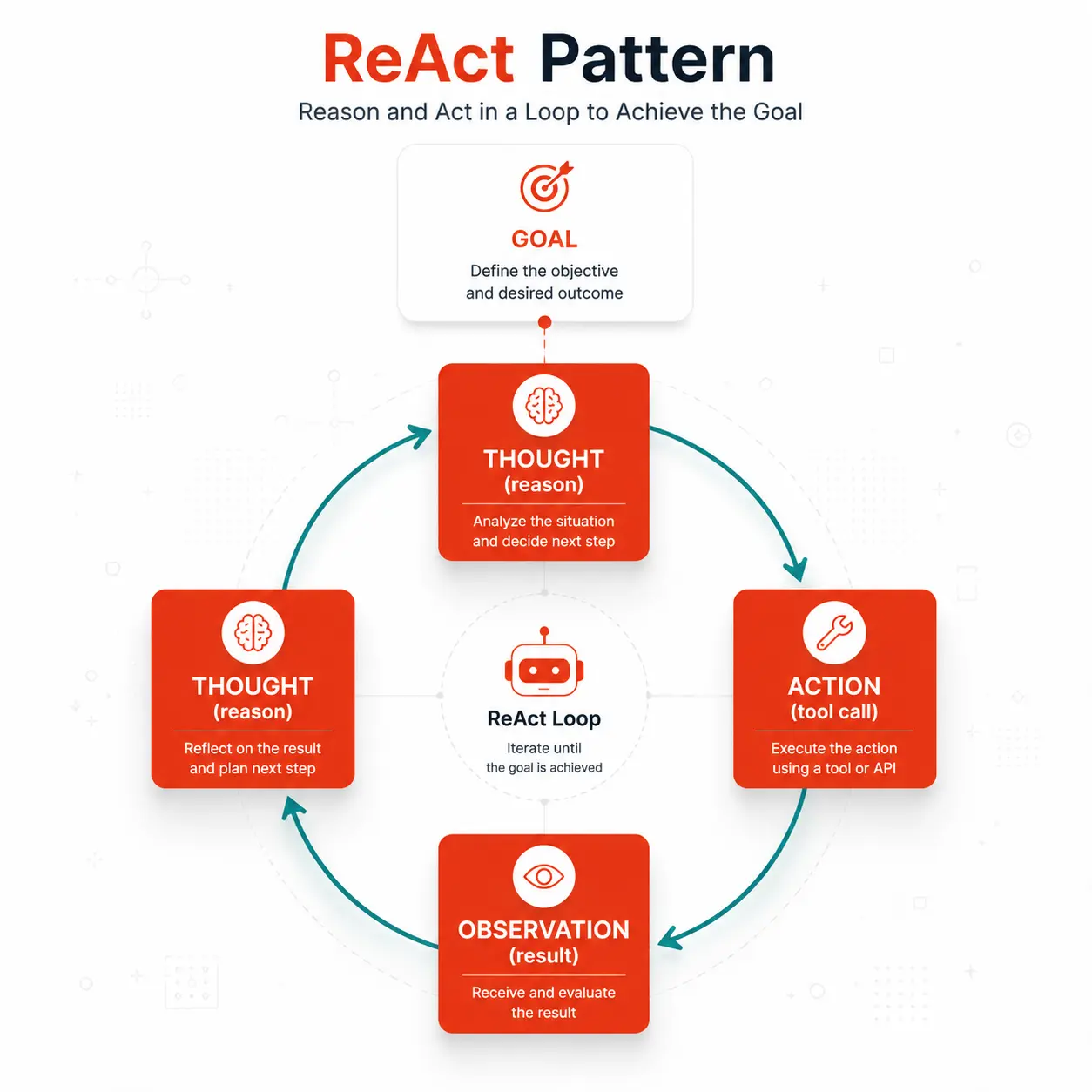
The ReAct pattern: the foundation of most agent planners
Before diving into specific strategies, you need to understand ReAct because almost every modern agent planning system either implements it, extends it, or reacts against its limitations.
ReAct stands for Reason + Act. It’s a prompting and execution pattern introduced in a 2022 paper from Google Research that interleaves reasoning traces with action calls. The loop looks like this:
// ReAct loop (simplified)
while (!goalAchieved) {
thought = llm.reason(goal, history, observations); // "I need to find X first"
action = llm.decide(thought); // "call search_tool(X)"
observation = tools.execute(action); // "search returned: ..."
history.append({ thought, action, observation });
}The model thinks out loud before acting. The observation from each action feeds back into the next reasoning step. This creates a self-correcting loop where the agent can catch its own mistakes if it reasons about what it observed.
ReAct is powerful because it’s simple and works with any capable LLM. Its weakness is that it’s purely sequential: one thought, one action, one observation at a time. For complex tasks, that becomes a bottleneck.
The five major agent planning strategies
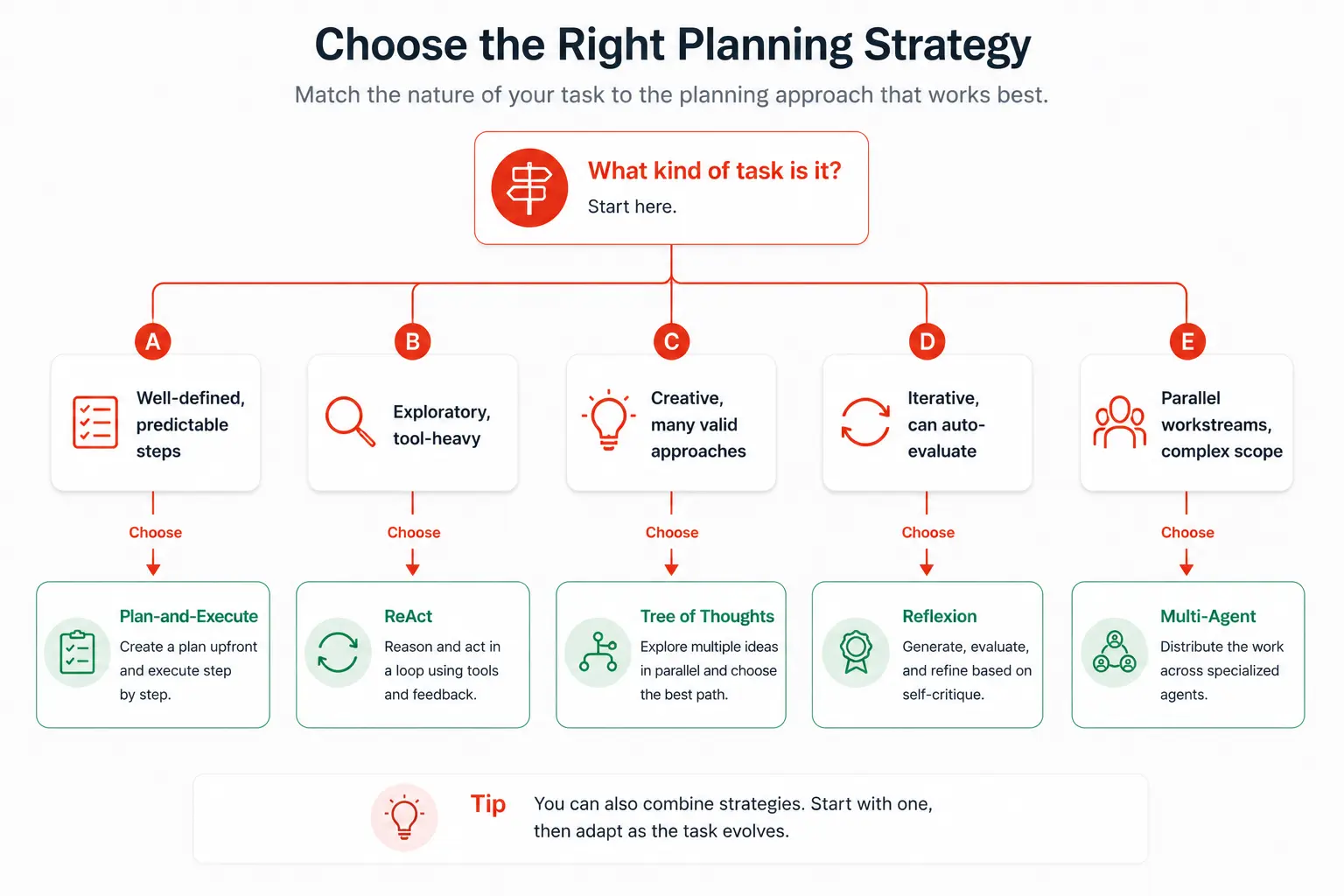
ReAct is the baseline. These five strategies build on or depart from it in important ways, each suited to a different class of problem.
1. Plan-and-execute
Plan-and-execute splits the planning and execution phases into two separate LLM calls. First, a planner model generates a complete step-by-step plan for the entire goal. Then, an executor model works through each step one at a time, updating the plan if needed.
// Plan-and-execute pattern
const plan = await planner.generate(goal);
// plan = ["Step 1: Search for competitors", "Step 2: Visit each site", ...]
for (const step of plan.steps) {
const result = await executor.run(step, context);
context.update(result);
// Re-plan if a step fails or reveals new information
if (result.requiresReplan) {
plan.revise(result.findings);
}
}The advantage: you get an auditable, human-readable plan upfront. You can inspect it before execution begins and catch obvious problems early. The disadvantage: the upfront plan can become stale quickly if early steps reveal information that changes what later steps should do.
Best for: Well-defined tasks where the path to the goal is mostly predictable. Report generation, data processing pipelines, and structured research tasks.
2. Chain-of-thought planning
Chain-of-thought (CoT) planning prompts the model to reason step by step before producing an answer or action. It doesn’t necessarily use external tools; instead, it uses internal reasoning as the “steps.” The model works through a problem like a mathematician showing their work, and the quality of reasoning improves significantly compared to direct answer generation.
In agentic contexts, CoT is used to improve the quality of individual decisions within a larger planning loop. Before calling a tool or taking an action, the agent reasons through the options: “Given what I know, what’s the most likely next step? What could go wrong? Is there a simpler way?”
Best for: Tasks requiring logical deduction, math, multi-constraint reasoning, or careful decision-making under uncertainty. Often combined with other strategies rather than used alone.
3. Tree of Thoughts (ToT)
Tree of Thoughts extends the chain-of-thought by exploring multiple reasoning paths in parallel, evaluating each, and pruning dead ends like a search algorithm applied to thinking itself.
Instead of committing to one chain of reasoning, the model generates several “thought branches,” evaluates how promising each one is, expands the best ones further, and eventually converges on the highest-quality plan. It’s computationally expensive, it requires multiple LLM calls per planning step, but it dramatically outperforms linear reasoning on tasks with many possible solution paths.

Best for: Creative problem-solving, strategy tasks, debugging complex systems, or any problem where the right answer isn’t obvious and multiple approaches are plausible. The tradeoff is cost and latency; use it when quality matters more than speed.
4. Reflexion (self-reflective planning)
Reflexion is a planning strategy where the agent evaluates its own performance after completing a task or a major step and stores those evaluations as verbal feedback to improve future attempts.
The key insight behind Reflexion: instead of just retrying a failed action, the agent writes a retrospective. “I failed because I searched for the wrong keyword. Next time, I should first identify the industry vertical before searching for company names.” That self-critique gets stored in memory and injected into the next attempt’s context.
// Reflexion loop
let attempts = 0;
while (!success && attempts < maxRetries) {
const result = await agent.execute(goal, memory.getReflections());
if (!result.success) {
const reflection = await agent.reflect(
`Task: ${goal}\nAttempt: ${result.trace}\nFailure: ${result.error}\n
What went wrong and what should I do differently?`
);
memory.storeReflection(reflection);
}
attempts++;
}Best for: Tasks where the agent can be evaluated on success/failure and where learning from mistakes across attempts is valuable. Code generation, test-driven development, and iterative writing tasks.
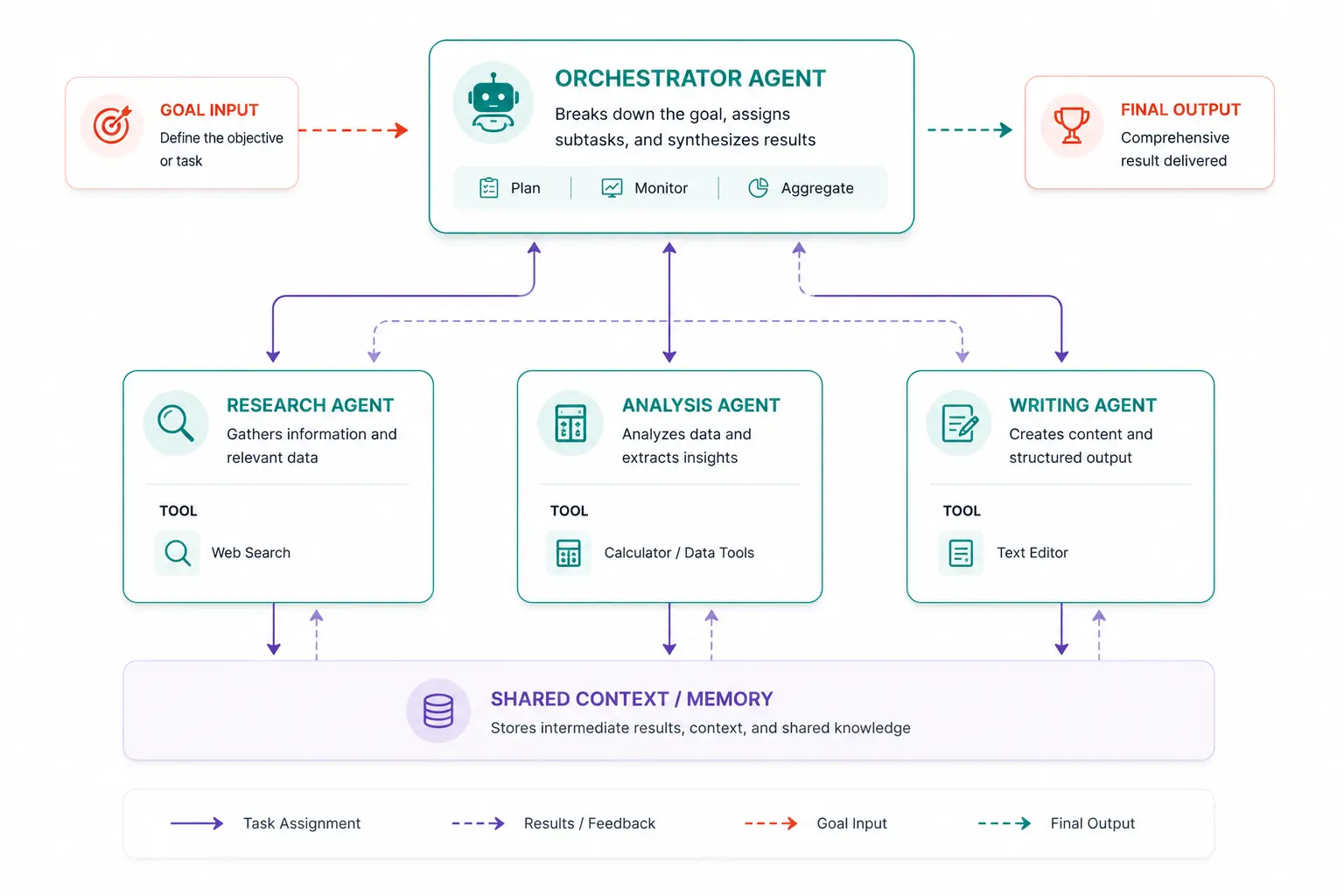
5. Multi-agent planning (orchestrator + subagents)
Multi-agent planning assigns different parts of a complex goal to specialized subagents, coordinated by an orchestrator. Instead of one agent doing everything, you decompose the goal horizontally into a researcher agent, a writer agent, a validator agent and the orchestrator manages their outputs into a coherent result.
This mirrors how real engineering teams work: you don’t have one person do every job. You assign tasks to the right specialist, and a project manager coordinates the output. Frameworks like CrewAI and AutoGen are built specifically around this model.
Best for: Long, complex workflows where different parts of the task require different skills or tools. Content pipelines, software development workflows, research-to-report pipelines. The tradeoff is coordination overhead and the complexity of debugging failures across agent boundaries.
Comparing the five planning strategies
| Strategy | Best task type | LLM calls per step | Handles surprises? | Complexity |
|---|---|---|---|---|
| ReAct | General tool-use tasks | 1 | Yes (inline) | Low |
| Plan-and-execute | Structured, predictable tasks | 1 + 1 per step | Partially | Medium |
| Chain-of-thought | Logic, math, constrained decisions | 1 (internal reasoning) | Somewhat | Low |
| Tree of Thoughts | Creative, open-ended problems | Many (parallel branches) | Yes (by design) | High |
| Reflexion | Iterative, evaluable tasks | 1 per attempt + reflection | Yes (across retries) | Medium |
| Multi-agent | Complex parallel workflows | N × subagent calls | Yes (per subagent) | High |
How planning fails and why it matters
Understanding failure modes is as important as understanding strategies. Agents fail at planning in specific, repeatable ways.
Anchoring on the wrong first step
This was my original bug. The agent commits to a direction based on early (potentially incorrect) information and executes the rest of the plan confidently against that bad premise. The fix: build in an explicit verification step after the first major action. “Before proceeding, confirm: does the result of step 1 match what was expected?”
Infinite loops and goal drift
Agents in a ReAct loop can get stuck retrying the same failed action, or gradually drift toward a different goal than the one originally specified. Always implement a max-step limit and a goal-check prompt every N steps: “Is what you’re currently doing still aligned with the original goal?”
Overplanning simple tasks
A plan-and-execute agent, handed a simple three-step task, sometimes generates a twelve-step plan with unnecessary complexity. Over-planning wastes tokens, increases latency, and introduces more decision points where things can go wrong. For simple tasks, ReAct or even a single-shot prompt is the better choice.
Failing to update the plan when observations change it
The agent makes a plan, starts executing, finds that step 2 contradicts the assumption behind step 4, but continues with the original plan anyway. This is a failure to adapt. Build explicit re-planning triggers: when an observation differs significantly from what the plan expected, pause and re-evaluate steps that depend on the now-invalid assumption.
Hallucinating tool capabilities
During planning, the model sometimes assumes it has access to a tool it doesn’t have, or assigns capabilities to a real tool that it doesn’t possess. Always pass an explicit tool manifest into the planner: name, description, input schema, and output format for each available tool. Never let the model assume what tools exist.
Practical guidance: choosing a planning strategy
Here’s the decision process I use when designing a new agent:
- How well-defined is the task? If the path to the goal is mostly known upfront, use plan-and-execute. If the task is exploratory and depends heavily on what you find along the way, use ReAct.
- Does it require creative problem-solving? If yes, and quality matters more than speed, use Tree of Thoughts for the high-stakes planning steps.
- Can success be evaluated automatically? If yes, add Reflexion. The agent can improve itself across retries without human intervention.
- Is the task too large for one agent? If it naturally decomposes into parallel workstreams requiring different tools or expertise, use multi-agent orchestration.
- When in doubt, start simple. ReAct handles a surprisingly wide range of tasks. Add complexity only when you’ve hit a real limit, not a theoretical one.
Mistakes developers make when implementing agent planning
Skipping the planning step entirely
For single-step tasks, fine. But for anything requiring more than two tool calls, going straight to execution without a planning phase produces fragile agents that get confused at the first unexpected result. Even a lightweight “think before you act” prompt dramatically improves reliability.
Using no termination condition
An agent with a planning loop and no hard stop condition is a runaway process. Always define: maximum number of steps, maximum cost or token budget, and an explicit “done” signal the agent must produce when it believes the goal is met. Then verify that signal before accepting the output.
Treating the plan as immutable
A plan is a hypothesis, not a contract. Build your planning system so the agent can and does revise its plan when observations warrant it. Agents that treat their initial plan as sacred make great progress right up until reality disagrees with step 3.
Not logging the reasoning trace
When an agent produces a bad output, you need to understand why. If you’re only logging the final answer, debugging is nearly impossible. Log the full thought-action-observation trace for every run. It’s the equivalent of a stack trace, the first thing you need when something goes wrong.
Choosing the most complex strategy first
Tree of Thoughts and multi-agent orchestration are impressive, but they’re expensive and hard to debug. Start with ReAct. Identify exactly where it fails on your specific task. Then add the minimum additional complexity that fixes that failure. Complexity compounds; every additional planning layer is another thing that can break.
Quick reference: planning systems at a glance
| Strategy | Core idea | When to use | Watch out for |
|---|---|---|---|
| ReAct | Think → act → observe → repeat | Default starting point for most agents | Sequential bottleneck on long tasks |
| Plan-and-execute | Generate a full plan first, then execute | Structured, predictable multi-step tasks | Stale plans when early results surprise |
| Chain-of-thought | Reason step by step before acting | Logic-heavy decisions within a larger plan | Verbose; not a substitute for tool use |
| Tree of Thoughts | Explore multiple reasoning branches, prune weak ones | Open-ended, creative, high-stakes problems | High latency and token cost |
| Reflexion | Self-critique after failure, improve on retry | Iterative tasks with automatic evaluation | Requires a clear success/failure signal |
| Multi-agent | Orchestrator delegates to specialized subagents | Complex parallel workflows | Coordination overhead is harder to debug |
Further reading and resources
- ReAct: Synergizing Reasoning and Acting in Language Models (arXiv), the original paper introducing the ReAct pattern, foundational reading for anyone building planning agents
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models (arXiv) full paper on ToT with benchmark results showing when it outperforms linear reasoning
- CrewAI agent concepts documentation, a practical guide to implementing multi-agent orchestration with role-based planning
My agent executing the wrong task perfectly was the best lesson I could have gotten. It showed me that execution capability without sound planning is just fast, confident, and wrong. The planning system is the part of an agent that asks, “Am I doing the right thing?” before pouring effort into “doing it well.”
Start with ReAct and get comfortable with the think-act-observe loop. Then layer in the strategies your specific task demands plan-and-execute for structure, Reflexion for iteration, Tree of Thoughts for hard problems, multi-agent for scale. Build the planning layer with the same care you’d give to the execution layer, and your agents will stop surprising you in the wrong ways.