The PR that nobody wanted to review
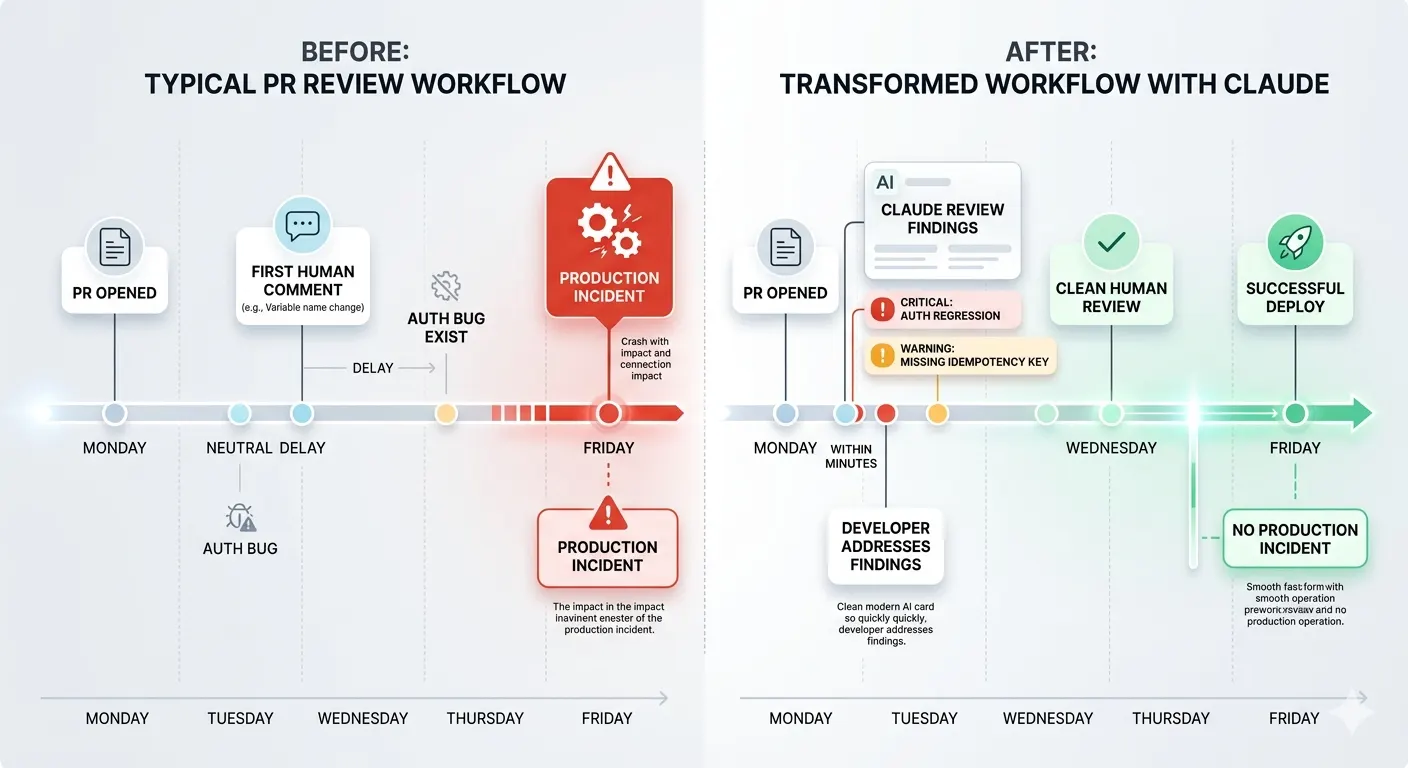
I shipped a feature in late February that touched eleven files across three services. I opened the pull request on a Thursday afternoon and tagged three reviewers. By Monday morning, I had one comment: a question about a variable name in a helper function. The critical auth logic in the middle of the diff had zero comments. The edge case in the payment handler that would later cause a production incident had zero comments.
Nobody was being negligent. The PR was just large, the team was busy, and human review capacity had not scaled to match the pace of code coming out of AI-assisted development. That is the problem Claude Code Review exists to solve.
Anthropic launched Code Review for Claude Code on March 9, 2026. Since then the feature has expanded significantly, and in late May and early June 2026, Anthropic added dynamic workflows that change what automated review can do at scale. This guide covers everything: how it works, how to set it up, what it costs, what it catches, and how it compares to the alternatives.
What Claude Code review is
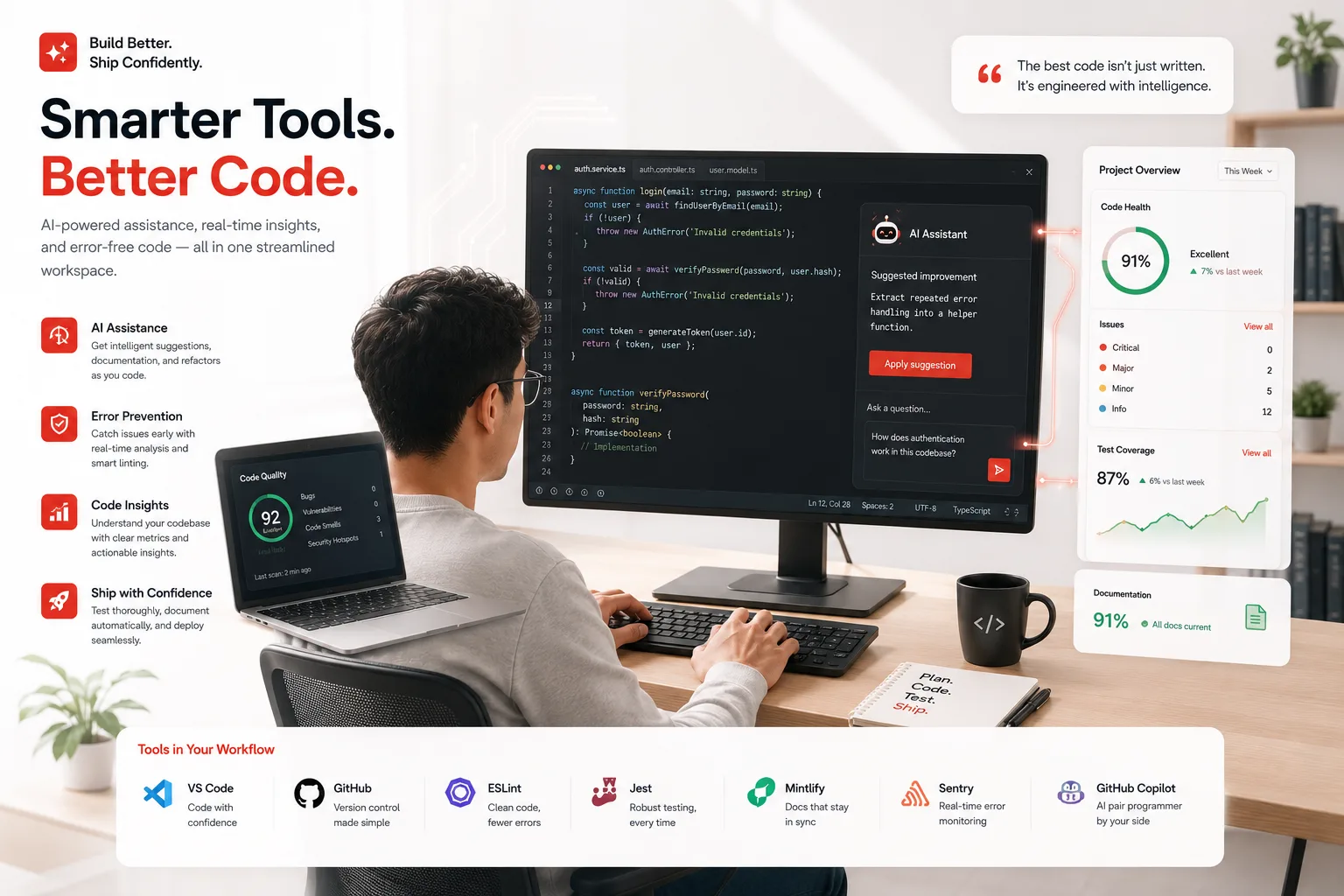
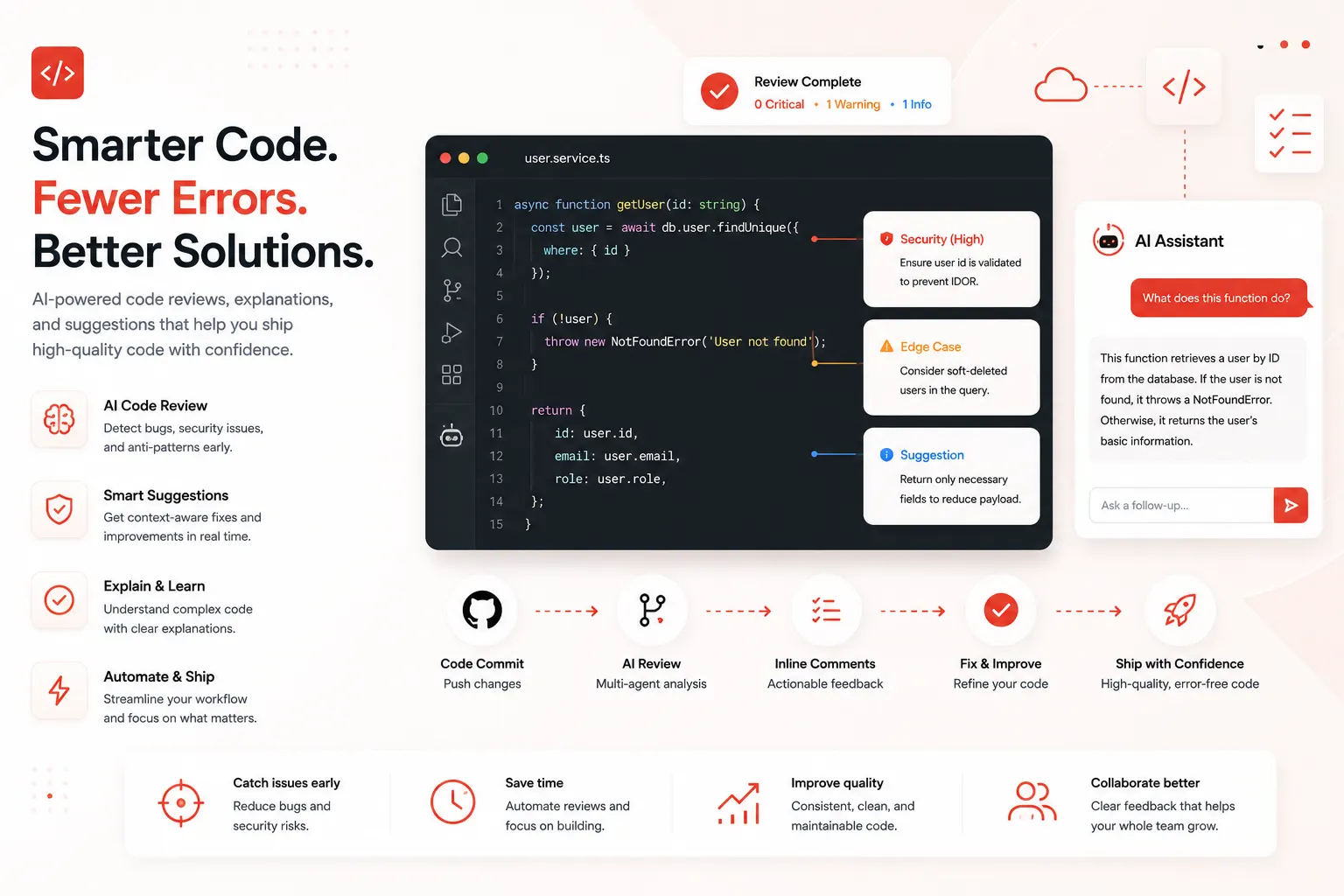
Claude Code Review is Anthropic’s automated pull request review system built directly into Claude Code. It analyzes your GitHub pull requests and posts findings as inline comments on the lines of code where it found issues. A fleet of specialized agents examines the code changes in the context of your full codebase, looking for logic errors, security vulnerabilities, broken edge cases, and subtle regressions.
The key phrase there is “in the context of your full codebase.” This is not a linter. It does not pattern-match against a ruleset. It reads the diff, the files the diff touches, adjacent code, and relevant history, then reasons about what the change actually does and whether it does it correctly.
Anthropic says the system runs multiple specialized agents in parallel, then verifies and ranks their findings before posting comments. The core pitch is logic-aware review, not style policing.
Findings are tagged by severity and posted as inline GitHub comments. It does not approve or block. Findings are added as inline comments with severity levels. Your existing review workflows stay intact. The final merge decision always remains with the team.
The problem it was built to solve
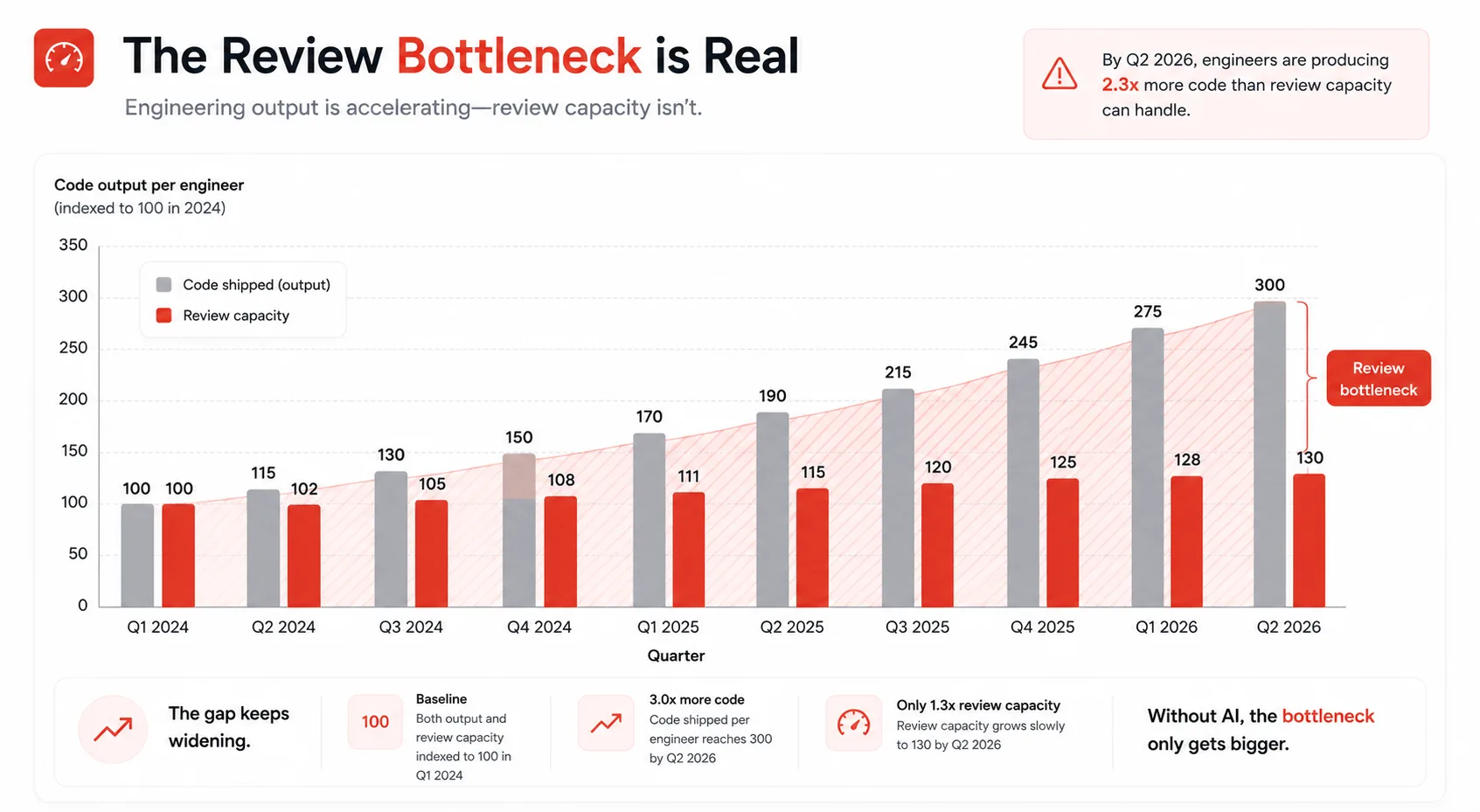
With the explosion of AI-generated code, Anthropic estimates that code output per engineer has grown by 200 percent in the last year. The result is that code reviews have become the main bottleneck in software development.
The math is simple and uncomfortable. If a developer can now write three times as much code per day with AI assistance, the review queue grows three times as fast. Hiring reviewers linearly to match that output is not realistic. And AI-generated code introduces a specific quality pattern that makes the problem worse.
AI-coauthored PRs show 1.7 times more issues than human-only PRs, according to Jellyfish’s 2026 data. The code looks clean, passes style checks, and compiles. The issues are logical, contextual, and subtle. They require the kind of reasoning that static analysis tools miss entirely.
Claude Code Review was built specifically for that gap: the logic errors, edge cases, and regressions that only appear when you understand what the code is supposed to do.
How the multi-agent architecture works
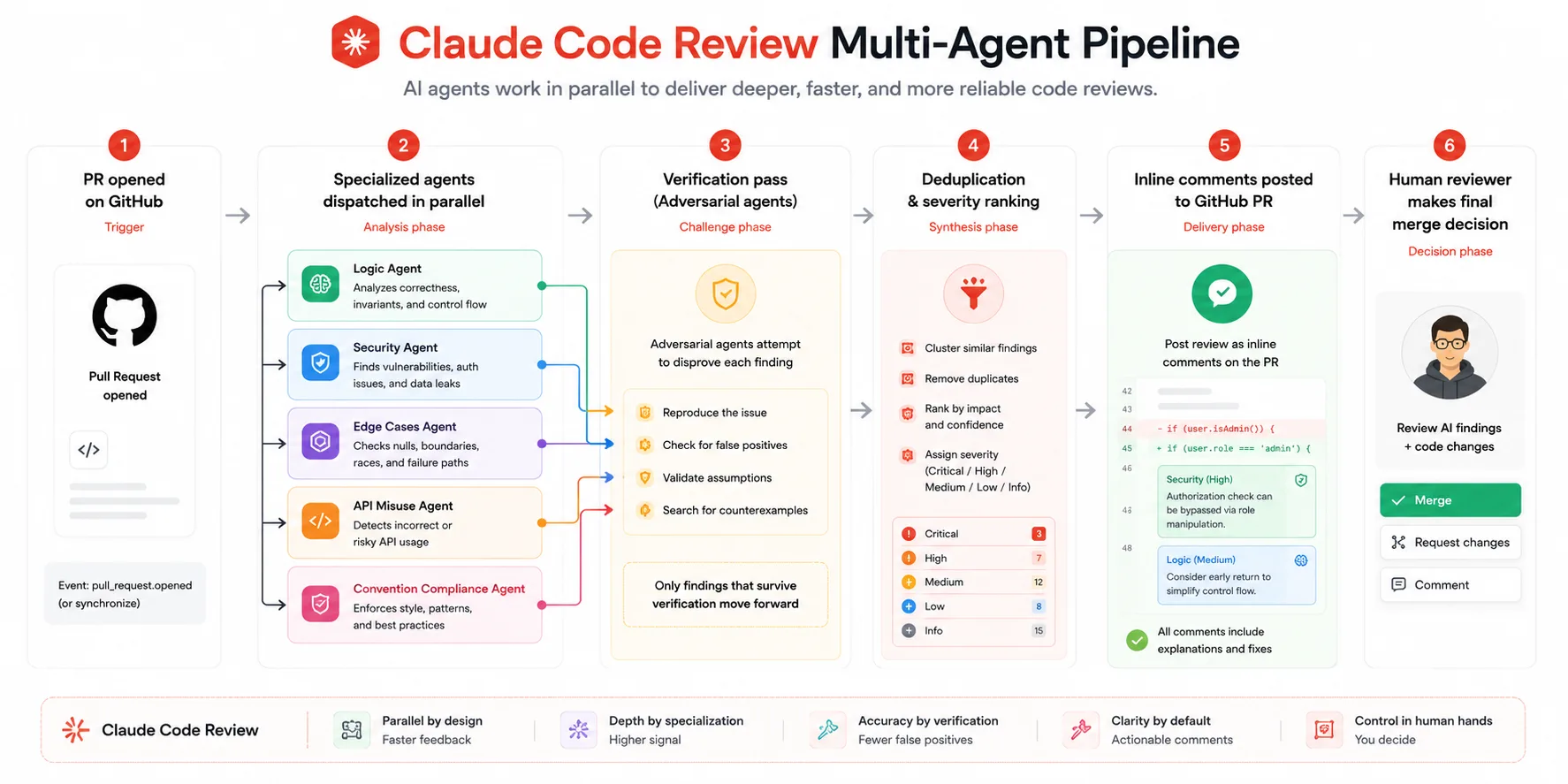
When a pull request opens on GitHub, the system automatically dispatches multiple specialized AI agents to analyze the code simultaneously. Each agent targets a different class of issue: logic errors, boundary conditions, API misuse, authentication flaws, and compliance with project-specific conventions. A verification step then attempts to disprove each finding before results are posted, a deliberate false positive filter.
That verification step is what separates Claude Code Review from most automated review tools. Other tools dump every potential concern as a comment and flood the PR with noise. Claude’s multi-stage filter runs an adversarial pass against its own findings before surfacing them.
In Anthropic’s internal data, 54 percent of pull requests now receive substantive comments, up from 16 percent with older approaches. Engineers marked less than 1 percent of findings as incorrect, which is unusually low for automated review tooling.
Each agent looks for a different class of issue, then a verification step checks results against actual code behavior to filter out false positives. Findings are deduplicated, ranked by severity, and posted as inline comments on the specific lines where issues were found.
Availability and access in June 2026
The access model is more nuanced in 2026 than it was at launch. There are now multiple ways to use Claude for PR review depending on your plan and preferred workflow.
Managed Code Review: Team and Enterprise
The managed Code Review service is available for Claude Team and Enterprise subscriptions. When a pull request opens, it dispatches several AI agents in parallel to inspect the diff, rank issues by severity, and post a summary review with inline comments. It does not approve or block the PR.
This is the fully automated, every-PR version. It requires no developer action once configured. The review runs automatically on every opened PR across enabled repositories.
/ultrareview: Pro and Max plans
Since April 2026, Pro and Max users can use /ultrareview, which launches a cloud-based multi-agent review at $5 to $20 per run. This runs from the local CLI, so it works regardless of your Git platform.
This is the on-demand version. You trigger it manually when you want a deep review before pushing, or before requesting human review on a large PR. It is the practical option for individual developers and small teams not on Team or Enterprise plans.
GitHub Actions: any plan with an API key
GitHub Actions with anthropics/claude-code-action requires just an API key and can be configured on any plan. This is the DIY path for teams that want automated PR review without a Team or Enterprise subscription. Setup takes more configuration work, but the cost is purely token-based and there is no subscription gate.
Manual review via CLI
If you are on an individual Pro or Max plan, you can still use the Claude Code CLI to review a diff locally before pushing, but you will not get the automated every-PR GitHub reviewer without a Team or Enterprise plan.
This works well as a pre-push check in a personal workflow. Run it, address the findings, then push a cleaner diff for human review.
Pricing: what Claude Code review actually costs
Cost is the most common question and the most common source of sticker shock. Here is the honest picture.
Claude Code Review uses token-based pricing. Anthropic documents a typical cost of $15 to $25 per review, depending on the size and complexity of the pull request. Larger, more complex PRs receive more agents and deeper analysis, so they cost more. There are no per-seat fees, but there is no built-in per-review or monthly spend cap, so total cost tracks your PR volume and size.
That pricing requires some arithmetic before you commit. A team doing ten PRs per day could spend $4,500 to $7,500 per month. For a team shipping that volume, the math against engineer time often works out. For a team shipping two or three PRs per day, the cost is more manageable, and the value case is clearer.
For teams shipping more than three to four PRs per day, the math is almost always favourable. The review that catches a production bug before it merges pays for itself many times over. The review that does not catch anything costs $15 to $25 and keeps your team shipping with confidence.
The /ultrareview option at $5 to $20 per run is the cost-conscious alternative for individual developers who want the multi-agent depth without the automated every-PR cost.
How to set up Claude Code review: step by step
Setup for the managed review service has two phases: admin configuration and repository enablement.
Step 1: Connect GitHub to your Claude organization
Go to claude.ai/admin-settings/claude-code in your organization’s Claude admin panel. Click “Connect GitHub” and install the Claude GitHub App. During installation, select which repositories you want to enable reviews on. You can choose all repos or specific ones.
The GitHub App installation requires organization admin permissions on GitHub. If you are not the GitHub org owner, you will need to coordinate with whoever holds that role before completing this step.
Step 2: Set a monthly spend cap
Set your monthly spend cap under Settings, then Usage Controls. Given that reviews average $15 to $25, a team doing ten PRs per day could spend $4,500 to $7,500 per month.
Set the cap before enabling repositories. There is no built-in per-review cap, so the spend cap is your primary cost control mechanism. Start conservatively and adjust once you have two to three weeks of data on your actual per-review costs.
Step 3: trigger your first review
Commenting @claude review starts reviews on a PR in any mode. On a newly configured repository, open any PR and post that comment to trigger the first review manually. This confirms the integration is working before the automatic trigger fires on production PRs.
Step 4: Create CLAUDE.md and REVIEW.md
This is the step that separates a generic review from a review that understands your codebase. These two files tell the review agents what matters in your specific project.
Code Review reads your repository’s CLAUDE.md files and treats newly introduced violations as nit-level findings. If your PR changes code in a way that makes a CLAUDE.md statement outdated, Claude flags that the docs need updating, too. Claude reads CLAUDE.md files at every level of your directory hierarchy, so rules in a subdirectory’s CLAUDE.md apply only to files under that path.
REVIEW.md gives you even finer control over what the review agents prioritize:
# REVIEW.md — Project-specific review priorities ## Prioritize findings about: - Authorization regressions across admin and customer-facing paths - Idempotency in webhook handlers (double-delivery is a real production risk) - Missing transaction boundaries on billing writes - Async jobs that can double-send emails, refunds, or notifications - Input validation missing on any public-facing endpoint ## Deprioritize or skip: - Formatting and import order (handled by our linter in CI) - Naming-only comments without runtime risk - Style nits already covered by ESLint rules - Comments suggesting refactors unrelated to the PR scope ## Context for the agents: - This is a payment processing service. Auth and billing paths are highest severity. - We use Stripe webhooks. Idempotency keys must be set on all webhook handler responses. - The Customer model is used by both admin and end-user flows. Scope bugs here cause data leakage. - All database writes to orders and invoices must be wrapped in transactions.
A well-written REVIEW.md dramatically improves signal-to-noise ratio. Without it, the agents apply general best practices. With it, they apply your team’s specific priorities and understand which failure modes matter most in your architecture.
Dynamic workflows: the June 2026 capability that changes scale
The most significant development in Claude Code review since launch is dynamic workflows, introduced on May 28, 2026 and updated in early June.
With dynamic workflows, Claude Code can now write its own orchestration scripts and spin up tens to hundreds of parallel subagents within a single session. Those subagents divide the work, check each other’s findings, and hand you a single coordinated result, without requiring you to build out a full agent pipeline yourself.
For code review specifically, this means tasks that were previously too large for a single review session are now tractable. Codebase-wide audits let Claude search a service or repository in parallel, then run independent verification on every finding. The same pattern works for security hardening, checking authentication, input validation, and unsafe patterns across an entire codebase.
The real-world scale is remarkable. Jarred Sumner used dynamic workflows to port Bun from Zig to Rust with 99.8 percent of the existing test suite passing, roughly 750,000 lines of Rust, in eleven days from first commit to merge. One workflow mapped the right Rust lifetime for every struct field. The next step wrote every .rs file as a behavior-identical port, with hundreds of agents working in parallel and two reviewers on each file.
For teams running periodic security audits or architecture reviews across large codebases, dynamic workflows replace what was previously a multi-day manual exercise with an overnight automated job.
The trigger keyword for dynamic workflows is now “ultracode” after a recent rename. The word “workflow” no longer triggers a run automatically, but asking for one in plain language still works. On Max and Team plans, dynamic workflows are on by default. Enterprise plans have them off by default, with admins enabling them in Claude Code settings.
Scheduled reviews: automating recurring work
March 2026 also brought scheduled tasks to Claude Code, and they compose naturally with the review capabilities.
You give Claude a prompt, attach one or more repos, choose a schedule, and add the environment and connectors it needs. Then it can run even when your computer is off. That makes Claude Code useful for ongoing operational work like reviewing open PRs every morning, checking CI failures overnight, syncing docs after merges, or running dependency audits every week.
Cloud auto-fix moved Claude further into post-PR work. Web and mobile sessions can now automatically follow PRs, fix CI failures, and address comments in the cloud so you can return to a ready-to-go pull request.
The practical pattern that many teams now run: a scheduled task that reviews all open PRs every morning before standup. Engineers arrive to a triage-ready list of findings sorted by severity. Humans spend their review time on judgment calls, not on hunting for the obvious issues.
# Example: Schedule a nightly PR audit using Claude Code CLI # Creates a recurring task that runs at 6 AM daily /schedule "Review all open PRs in the payments-service repo. For each PR: 1. Run a full review focusing on auth paths, transaction boundaries, and idempotency 2. Post findings as inline comments if not already reviewed today 3. Flag any PR with a CRITICAL finding to the #engineering-alerts Slack channel 4. Generate a morning triage report and post it to #code-review-digest Use the REVIEW.md in payments-service as your priority guide." # Cadence: daily at 06:00 UTC # Schedule confirmed: job ID pr-nightly-audit-7f3a, next run: 06:00 UTC
Claude Code review vs the alternatives
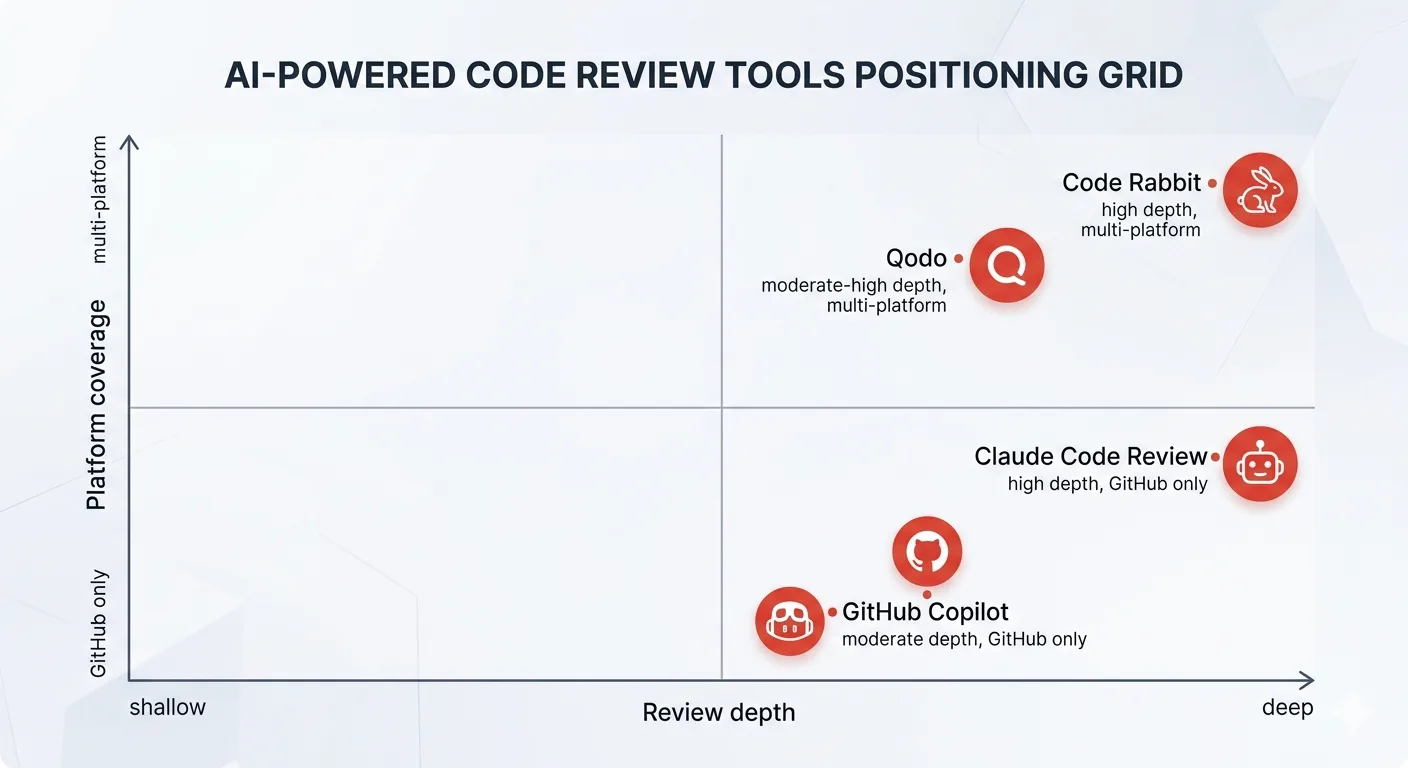
Claude Code Review did not launch into an empty market. CodeRabbit, GitHub Copilot, and Qodo were already established when it arrived in March 2026. Here is where each tool genuinely wins.
Claude Code review vs CodeRabbit
Claude Code Review is the premium option for teams deeply invested in the Claude ecosystem. The multi-agent architecture produces the highest per-PR analysis depth in the category. CodeRabbit is the most complete, most versatile AI code review tool available. It supports the most platforms, integrates the most security tools, and offers the best value per dollar for most team sizes.
The platform support gap is real. Claude Code Review is GitHub-only as of June 2026. CodeRabbit supports GitHub, GitLab, Azure DevOps, and Bitbucket. If your team is on GitLab or Azure DevOps, CodeRabbit is the answer by default.
On GitHub, the quality comparison is closer. CodeRabbit scores 51.5 percent F1 versus Copilot’s 44.5 percent on the Martian Code Review Bench, catching more bugs with 52.5 percent recall versus 36.7 percent. Claude Code Review’s 1 percent false positive rate and 54 percent substantive comment rate suggest it competes at or above CodeRabbit’s level for logic-heavy review, though independent benchmark data directly comparing the two is still limited.
The pricing model also differs significantly. CodeRabbit charges $24 per user per month for unlimited reviews. Claude Code Review charges $15 to $25 per review regardless of team size. For high-volume teams, the flat per-seat model of CodeRabbit is more predictable. For teams doing lower PR volume with a need for deep analysis, Claude Code Review’s per-review pricing can come out cheaper.
Claude Code review vs GitHub Copilot
GitHub Copilot Code Review is the easiest to adopt and the best value for teams already paying for Copilot. It sacrifices some depth for speed and precision, which is the right trade-off for many teams.
Copilot holds roughly 42 percent of the AI coding tools market and has processed over 60 million code reviews. The March 2026 agentic architecture significantly improved its code review capabilities.
Copilot’s advantage is bundling. If your team already pays for Copilot Business or Enterprise, the code review feature adds zero marginal cost. For teams choosing between adding a new tool versus getting more value from a tool they already pay for, Copilot review is the obvious starting point.
The depth comparison favours Claude Code Review for complex, logic-heavy PRs. Copilot’s review is faster and costs nothing extra, but Claude’s multi-agent verification pass and REVIEW.md customization produce more precise findings on the issues that actually matter.
Claude Code review vs Qodo
Qodo is the enterprise-grade choice for teams that need code verification, governance enforcement, and test generation alongside reviews. Qodo explicitly positions itself against what it calls “software slop” from AI coding agents, and its test generation alongside review is a capability Claude Code Review does not replicate natively.
If your team wants the review to also generate test cases for the scenarios it flags, Qodo is the stronger choice. If you want the deepest per-finding analysis with customization through CLAUDE.md and REVIEW.md, Claude Code Review wins that comparison.
Comparison table: Claude Code review versus the alternatives
| Feature | Claude Code Review | CodeRabbit | GitHub Copilot Review | Qodo Merge |
|---|---|---|---|---|
| Multi-agent parallel review | Yes (native) | Yes (Deep Review agent) | Yes (March 2026 update) | Partial |
| False positive rate | Under 1% | Low (51.5% F1 score) | Moderate (44.5% F1 score) | Low |
| GitHub support | Yes | Yes | Yes | Yes |
| GitLab support | CLI beta only | Yes (full) | No | Yes |
| Custom review rules | CLAUDE.md + REVIEW.md | Learnable preferences | Limited | Yes (governance rules) |
| Test generation alongside review | No (separate workflow) | Partial | No | Yes (core feature) |
| Pricing model | $15-$25 per review (token-based) | $24/user/month (flat) | Included with Copilot plan | Contact for pricing |
| Free tier | Via /ultrareview on Pro/Max | Yes (open-source repos) | Yes (limited) | No |
| Scheduled/recurring reviews | Yes (Routines + scheduled tasks) | Yes | No | No |
| Dynamic workflows for large audits | Yes (ultracode, May 2026) | No | No | No |
| Access requirement | Team or Enterprise plan | Any plan | Copilot Business or higher | Any plan |
What Claude Code review catches that static analysis misses
Understanding the actual catch categories helps you calibrate expectations and explain the value to engineering leadership.
Static analysis tools like ESLint, SonarQube, and CodeQL are excellent at what they do. They catch known bad patterns, enforce style rules, and flag code that matches vulnerability signatures. Claude Code Review does not replace them. It adds a layer above them.
The logic error category is where Claude Code Review produces the most unique value. A function that handles a state transition correctly for five of six possible states and silently corrupts data on the sixth will pass every static analyzer you run at it. Claude Code Review reasons about the state machine and notices the missing case.
Authorization regressions are another high-value category. A PR that adds a new endpoint and correctly implements auth on four of five code paths will pass code review by a tired human who scanned the diff quickly. Claude Code Review’s security-specialized agent reads the full auth pattern in the codebase, checks the new endpoint against it, and flags the uncovered path.
Edge case handling in async code is the third major category. Double-send bugs, race conditions in webhook handlers, missing idempotency keys on operations that will be retried: these require understanding the operational context of the code, not just its syntax. A REVIEW.md that gives the agents that operational context produces findings in this category that no pattern-matching tool can replicate.
What to put in your CLAUDE.md for better reviews
CLAUDE.md is the file Claude Code reads to understand your project’s rules and conventions. Code Review reads your repository’s CLAUDE.md files and treats newly introduced violations as nit-level findings. Claude reads CLAUDE.md files at every level of your directory hierarchy, so rules in a subdirectory’s CLAUDE.md apply only to files under that path.
The sections that most improve review quality are architectural constraints, security requirements, and known edge cases the team has already identified.
# CLAUDE.md — Root project rules ## Architecture - All database access goes through the repository layer. Direct ORM calls in service or controller files are architectural violations. - The UserService must never be imported by any billing module. Billing has its own user lookup via BillingUserAdapter. - API responses must be typed through our ResponseSchema validators. Raw dict responses are not acceptable in any public endpoint. ## Security requirements - All admin endpoints require both authentication AND authorization checks. Auth decorators alone are not sufficient. - Webhook handlers must set idempotency keys using the event_id from the payload. Missing idempotency keys are CRITICAL findings. - No direct string interpolation in SQL. All queries must use parameterized statements. - Environment variables must never be logged. Scrub them before any log call. ## Known edge cases to flag - The Order model has a soft-delete pattern. Queries without .filter(deleted_at=None) return deleted records silently. - Refunds above $500 require a second approval record in the AuditLog table before processing. Single-step refunds above $500 are bugs. - The notification service is not idempotent. Calling it twice sends two emails. All notification calls must be guarded by a sent_at check. ## Deprioritize during review - Import ordering (handled by isort in pre-commit) - Docstring format (handled by a separate docs audit) - Type annotation completeness on internal-only helper functions
Common mistakes teams make with Claude Code review
These are the failure patterns that appear most consistently across teams that set up the feature and then stop trusting it within a few weeks.
Skipping REVIEW.md and CLAUDE.md
Without these files, the review agents apply general best practices to a codebase they know nothing about. The findings will be accurate in an abstract sense and nearly useless in a specific sense. A payment service with idempotency requirements and a content platform with rate-limiting requirements need completely different review priorities. A generic review produces generic findings that engineers stop reading.
Setting a no-spend cap
Token-based pricing with no spend cap and a high-volume PR workflow is a combination that produces unexpected monthly bills. Set the spend cap before enabling repositories, not after the first invoice arrives.
Treating findings as mandatory changes
Claude Code Review posts findings as inputs to human judgment, not as required changes. The finding that a function is missing an edge case might be correct. It might also be that the edge case is handled three layers up in the call stack, and the agent did not have that context. Engineers should read findings critically, not implement them blindly. The tool reduces review burden; it does not eliminate the need for engineering judgment.
Ignoring the severity ranking
Every finding is tagged with a severity level. The correct workflow is to read CRITICAL findings first, address or explicitly dismiss each one, then move to WARNING findings. Reading comments in chronological order and addressing them top-to-bottom treats a missing idempotency key the same as a variable naming suggestion. That is not the intended workflow, and it produces inconsistent outcomes.
Not running /ultrareview locally before large PRs
Teams on Team or Enterprise plans sometimes skip the local review because the automated review will run on PR open anyway. The problem is that addressing findings after the PR is open means pushing additional commits, which triggers another round of human review requests. Running /ultrareview locally before opening a large PR means the diff that human reviewers see has already had its obvious issues addressed. Human review time concentrates on judgment calls, not on the findings the AI would have caught.
Quick reference: Claude Code review setup checklist
| Task | Where | Notes |
|---|---|---|
| Connect GitHub to Claude org | claude.ai/admin-settings/claude-code | Requires GitHub org admin permissions |
| Set monthly spend cap | Settings then Usage Controls | Do this before enabling repos |
| Enable target repositories | GitHub App installation | Can choose all repos or specific ones |
| Create root CLAUDE.md | Repository root | Architecture, security rules, and known edge cases |
| Create REVIEW.md | Repository root | Review priorities and deprioritizations |
| Add subdirectory CLAUDE.md files | High-risk subdirectories (auth, billing, payments) | Rules apply only to files under that path |
| Test with @claude review comment | Any open PR | Confirms integration before automatic trigger fires |
| Schedule recurring PR audit (optional) | Claude Code CLI via /schedule | Useful for morning triage before standup |
| Enable Ultracode for large codebase audits | Claude Code settings (Max, Team plans) | On by default for Max and Team; admins enable for Enterprise |
Further reading
- Code Review for Claude Code: Official Anthropic Documentation
- Set Up Code Review for Claude Code: Anthropic Help Center
- Introducing Dynamic Workflows in Claude Code: Anthropic Blog
The review bottleneck is solvable. This is how you solve it.
That PR from February, the one with eleven files and one comment about a variable name, is what convinced me to take automated review seriously. The auth logic that nobody caught in human review made it to production. We caught it three weeks later when a security researcher filed a responsible disclosure report. We were lucky.
Claude Code Review was launched two weeks after that incident. I have been using it since March, and the workflow change is real. Critical findings now surface within minutes of PR open. Human reviewers spend their time on architecture decisions and context that the AI cannot have, not on hunting for the obvious things.
The setup takes an afternoon. The CLAUDE.md and REVIEW.md files take another afternoon to write well. After that, the review bottleneck that was quietly becoming the largest risk in AI-assisted development teams starts to close.
The code is shipping faster than human review can keep up with. The tools to handle that exist now. Using them is a decision, not a technical obstacle.